Image segmentation is a crucial task in computer vision, where it is essential to identify and separate objects or regions within an image. However, when working with low-power edge devices, the computational resources are limited, making it challenging to train deep neural networks for image segmentation. In this article, we will explore various advanced neural network architectures that have been proposed specifically for resource-constrained scenarios, including MobileNetV3-Small, ERFNet, M2U-Net, and T-Net.
Despite the progress made in developing these architectures, there is still a notable gap in evaluating their performance on actual low-power edge devices. To address this issue, our work introduces a comprehensive evaluation of these architectures on two low-power edge devices: Jetson TX1. Our findings demonstrate that MobileNetV3-Small and ERFNet achieve the best results among all the evaluated architectures, with a trade-off between accuracy and computational efficiency.
Our architecture is based on an encoder-decoder structure with skip connections and special hidden dimensions (16, 32, 64). Each block consists of a 3×3 convolutional layer with batch normalization and ReLu activation, followed by a 1×1 convolutional and a depth-wise convolution block. Depending on the type of the block, max pooling/unpooling operations are applied. Skip connections are placed both between corresponding encoder and decoder modules and before and after each block to facilitate information flow. The final output segmentation map is produced by a final convolutional layer.
In summary, this article provides a comprehensive overview of various advanced neural network architectures designed for image segmentation on low-power edge devices. By evaluating these architectures on actual low-power edge devices, our work sheds light on the trade-offs between accuracy and computational efficiency, which is crucial for developing practical applications in computer vision.
Electrical Engineering and Systems Science, Image and Video Processing
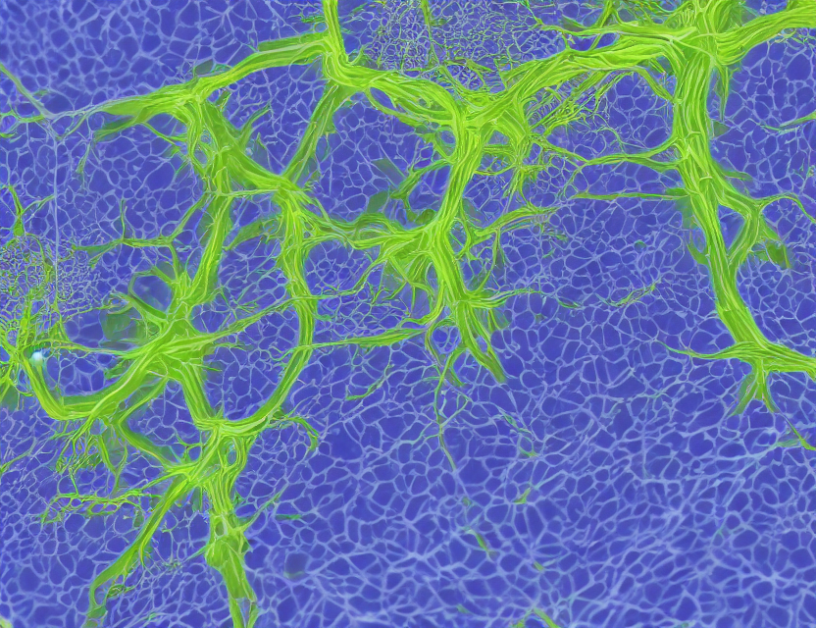
Retinal Vessel Segmentation via Efficient and Accurate Deep Learning Models

Electrical Engineering and Systems Science
Optimizing Grassmann Constellations for Efficient Data Transmission

Electrical Engineering and Systems Science
Optimizing Battery Size for Off-Grid Renewable Hydrogen Production: A Techno-Economic Analysis

Audio and Speech Processing