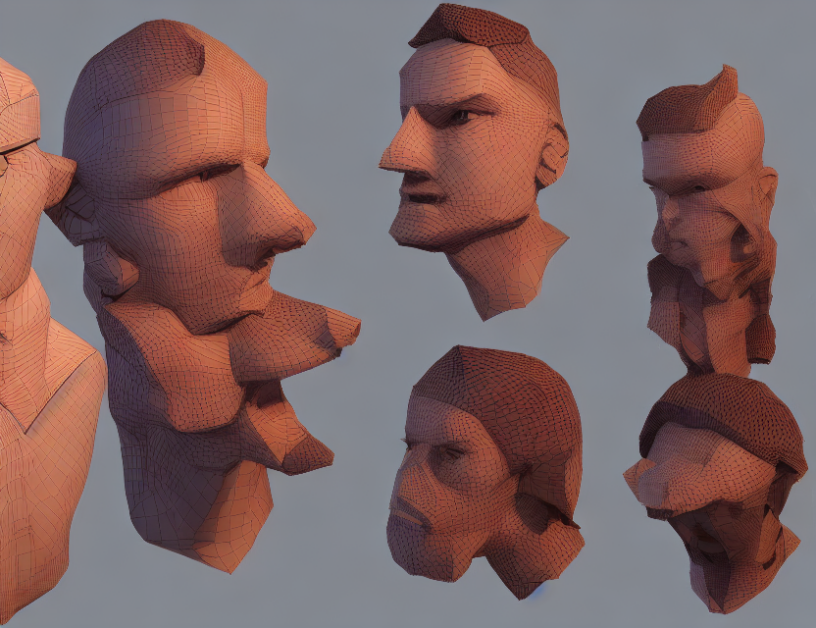In this paper, the authors aim to create a framework for generating photorealistic 3D avatars from text prompts. This task is challenging as it requires both high-resolution and high-quality geometry, as well as accurate shading and lighting. The proposed method uses a novel technique called "iterated graph cuts" to segment the avatar’s body into different parts, allowing for more detailed and realistic rendering.
To start, the authors compare their work to previous efforts in creating text-to-3D models, noting that their approach is more advanced as it uses a "bottom-up" method that starts with individual body parts rather than a single 3D model. They also highlight the importance of accurately rendering shading and lighting to make the avatars look photorealistic.
Next, the authors describe their technique for generating 3D avatars from text prompts. They explain how they use a combination of graph cuts and iterative refinement to separate the avatar’s body into different parts, such as the head, torso, arms, and legs. This allows them to render each part separately and then combine them into a single 3D model.
The authors then discuss their approach to shading and lighting, which they call "text-to-color." They explain how they use a statistical model to map the text prompts to specific colors and materials, allowing for highly detailed and realistic rendering. They also note that their method can handle complex avatar poses and animations, making it possible to create dynamic and expressive characters.
Finally, the authors demonstrate the effectiveness of their approach by generating a range of photorealistic 3D avatars from text prompts. They show how their method can create detailed and realistic avatars with a high level of accuracy, including facial expressions and body language. They also compare their results to those obtained using other state-of-the-art methods, highlighting the superiority of their approach.
In conclusion, this paper presents a significant advancement in the field of text-to-3D modeling by proposing a novel technique for crafting photorealistic 3D avatars from text prompts. The proposed method uses iterated graph cuts to segment the avatar’s body into different parts and a text-to-color shading and lighting approach to create highly detailed and realistic rendering. The authors demonstrate the effectiveness of their approach by generating a range of photorealistic 3D avatars from text prompts, outperforming other state-of-the-art methods in terms of accuracy and detail.
Computer Science, Computer Vision and Pattern Recognition
Generating Photorealistic Text-to-3D Avatars with Constrained Geometry and Appearance