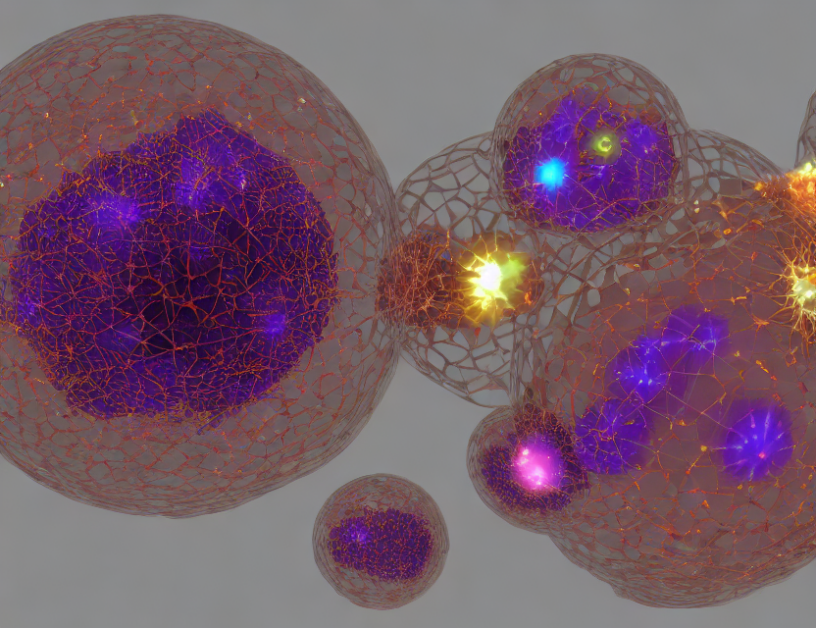
In this article, we present a novel approach for visualizing scattered data with high accuracy and efficiency. Our method leverages piecewise polynomial functions to represent field values and gradient information, which are then processed during a compositing sweep. By choosing the right parameters, we can balance approximation accuracy and performance.
To start, let’s define what we mean by "representative" attributes of the data set. These could be average or mean values or attributes chosen from any particle in a region of interest. We then abbreviate these representative attributes as φrepr = µreprαrepr.
The next step is to minimize the difference between the original data and its approximation, represented by ρreprζ3. This process involves accumulating contributions along each ray, classifying and compositing the result.
In Section 3, we present a way to efficiently compute optimal approximations for single particle contributions during the first sweep. In Section 4, we describe a pitfall that our higher-order approximation scheme involves and develop an improvement of our method to overcome this difficulty.
We then analyze the approximation errors implied by our scheme and discuss the choice of the major parameters like the approximation order, before concluding our work in Section 6.
In summary, our approach offers a promising solution for visualizing scattered data with high accuracy and efficiency. By choosing the right parameters, we can optimize the balance between approximation accuracy and performance. While our findings are still to be proven in practice, we believe they will help advance scientific visualization of scattered data.
Quantizing Spherical Harmonics in SPH: A New Approach to Efficiently Represent Particles